wetlands <- readRDS("wetlands.rds")Correspondence Analysis
method
Correspondence analysis (CA) is an unconstrained ordination analysis used for unimodal relationships, preferably with ordinal abundance values.
Description
Correspondence analysis (CA) is a multivariate statistical technique designed to explore relationships between categorical variables within contingency tables. It is particularly useful for analysing patterns of association in large data sets where rows and columns represent categories or groups. In community assessments, this method is used when unimodal relationships are expected and may be more appropriate for assessing ordinal abundance scales or presence/absence matrices. The underlying statistic is a chi-squared distance.
As in the case of PCA, this method is susceptible to double zeros. It also has a pronounced arch artefact problem, which DCA attempts to fix.
Example
library(vegan)
library(vegtable)
# Reclasify abundance
wetlands$obs$abund <- cut(wetlands$obs$cover_perc,
breaks = c(0, 25, 50, 100), labels = FALSE)
wetlands$cross2 <- crosstable(abund ~ taxon_code + plot_id,
FUN = max, data = wetlands$obs,
na_to_zero = TRUE,
as_matrix = TRUE)
ca_ord <- cca(wetlands$cross2)
plot(ca_ord)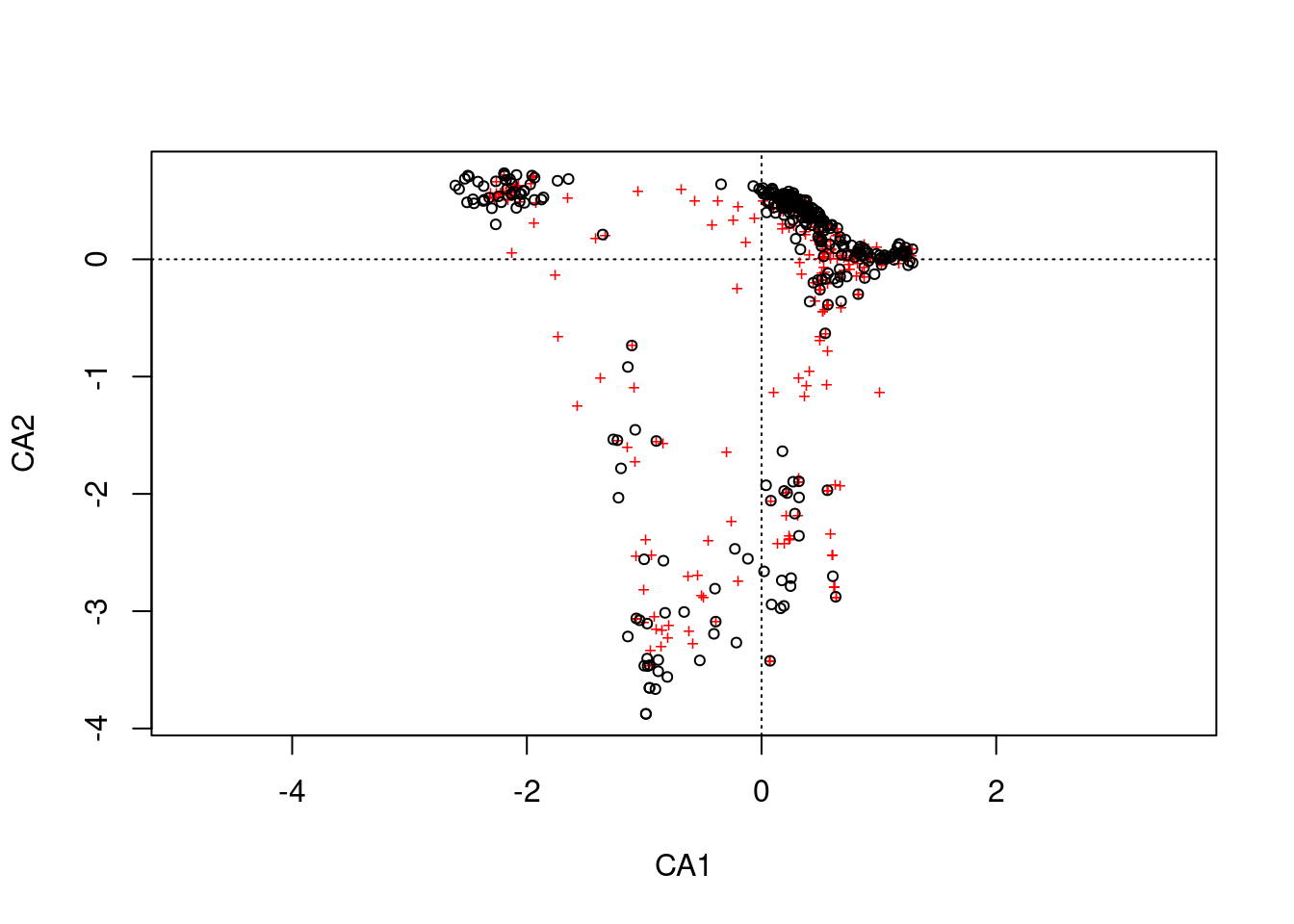
Alternative functions
vegan::cca()when only one table is provided as input.ade4::dudi.coa()